Poker and AI: Reporting from the 2016 Annual Computer Poker Competition

You��ve probably all seen something in the news about AI (artificial intelligence) recently, whether it��s self-driving cars, computers competing at the highest level in the ancient board game of Go, or the latest humanoid robots from Boston Dynamics. It��s a fast-moving field, and the problems that AI is tackling are all over the place.
Attending the 2016 AAAI Conference on Artificial Intelligence last month in Phoenix, I can confirm that this view is broadly accurate. There were something like 400 talks or posters plus a half-dozen keynotes discussing a dozen different concentrations of AI. Topics covered ranged from the ethics of AI and the future of jobs in a robot world, to very recent developments from DeepMind��s AlphaGo conquering the world��s most difficult board game, to rather old but still very cool work about drones flying in formation and automatically avoiding crashing into one another.
I didn��t go to all of the talks, nor even to all of the keynotes, but I did manage to learn a lot about the robot future. I also had a chance this year to participate in the 2016 Annual Computer Poker Competition with my own entry, and so wanted to share some from that experience as a way of providing an update on the latest in poker-playing AIs.
The Current State of Poker-Playing AIs
Before the main conference got underway, I spent a day at the AAAI Poker & Game Theory workshop where the discussion focused on our favorite card game.
It was there that Chairman Kevin Waugh announced the 2016 Annual Computer Poker Competition results, and as has happened every year since the competition��s inception, the winners used an approximate equilibrium finding method called CFR (counterfactual regret minimization) to win the competition. In fact, the first through fourth place finishers all used CFR, with the top three finishing within $2 per hand of each other over hundreds of thousands of $50/$100 no-limit hold��em heads-up hands.
This equilibrium-balancing approach is the same strategy used by the ��Claudico�� bot from Carnegie Mellon University, the one that played four heads-up specialists to a ��statistical draw�� last year over two weeks and 80,000 hands of play at a Pittsburgh casino. In fact, a scaled-down version of ��Claudico�� performed well at the ACPC, placing first in the Competition Crosstable and Total Bankroll Competition under the ��Baby Tartanian8�� monicker.
Meanwhile this year��s Instant Runoff Competition winner �� ��Slumbot�� �� is almost certainly stronger than last year��s best AI. By the way, if you��re curious to try your hand against one of this year��s better-performing entries, you can play against ��Slumbot�� here. (That��s a screenshot of ��Slumbot�� in action up top.) Matthew Pitt reports further on the results of this year��s competition in ��The Perfect Poker Bot Is Almost Here.��

With differences between the top robot players so close, it��s tempting to think that the programs are converging toward a single, unbeatable heads-up NLHE solution, especially since the University of Alberta proved last year that they did indeed converge to an unbeatable player in heads-up fixed-limit hold��em. (I still don��t understand how that AI never four-bets AxAx preflop.) But heated discussions over Saturday's lunch seem to suggest that �� despite the title of Matthew��s article �� this matter of a perfect strategy for no-limit hold'em is far from settled.
Unlike heads-up limit, the NLHE game space is too large to solve outright, just based on bet-sizing alone. The winning CFR strategies consider as many as 11 bet sizes when making an initial bet, but usually a much smaller number of raise sizes, and basically are down to all-in/call/fold as they look at three-bets and four-bets deeper into the search tree.
Among other things, this makes the betting strategies somewhat conservative. Also, narrowing the bet-sizing that it��s willing to consider could open it up to exploitation by in-between bet sizes, as these bets get mapped to either bets that are too big or bets that are too small, given the pot size. Of course, in practice, it is really hard to find these weaknesses or a specific hand.
It is easy to argue that CFR bots don��t really create artificial intelligence. They run an equilibrium-balancing process for weeks �� or months �� then at game time, they look up and apply the closest match to the cards and bets on board. In other words, these systems don��t adjust to opponent weaknesses, nor do they even look at previous hands against an opponent, although this match-state information is available throughout the ACPC competition.
Actually, the logs from last year��s competition are public, so each subsequent class of poker AIs tries to beat CFR by training AIs to looking for patterns within those hundreds of thousands of heads-up situations from previous contests. One could argue that is approach might actually be closer to artificial intelligence, but that��s for the reader to judge.
My Own Entry: ��Poker-CNN��
Effectively tied for fifth in this year��s Instant Runoff Competition were ��Poker-CNN,�� a deep learning neural network by yours truly, and ��Hugh," which from what I was told is a hand-calibrated system created by a famous mathematician, with input from one of the top online heads-up poker players in the world. (The competition doesn��t publish the poker AIs�� authors, nor what methods they used, so it��s up to the ��Hugh�� authors if they want to identify themselves. I��d love to hear their story.)
After belly-aching for a while about training my bot from self-play against a gradually improving player for the ACPC competition, I simply went with an approach that tries its best to replicate CFR. With some caveats not worth getting into here, I trained on last year��s winners�� logs, asking my network to predict the average strategy used by the winning players.
To make an NLHE decision, I turned it into a three-part question. Given the cards we see and the bets made so far, I asked
- What is aggression percentage? In other words, how often do I bet or raise in this spot?
- If we decide to bet or raise, how do our bet sizes range (from min-bets to all-ins)?
- If we decide not to bet, what is our folding percentage?
The nice thing about breaking up a strategy into these questions is that I can ask my deep neural network to predict each of these answers at the same time, thus jointly learning the patterns needed for several different views on the game. The aggression percentage is just one number (from zero to one). Often, the strategy calls for 0% aggression while sometimes it is close to 100%, although it��s usually somewhere between 10% and 60%.
Choosing how much to bet is trickier. What you really want is a continuous distribution over every possible bet amount, but in practice, ��Poker-CNN�� learns the likelihood of making a few specific bet sizes, then fills in the points in between. I went with the bet sizes of
- min-bet
- 20% pot
- 50% pot
- pot
- 1.5x pot
- 3x pot
- 10x pot
- all in!
Some of these bets may look weird, and in retrospect I wish I��d used a larger number of bets to consider. But to handle all situations that the AI may encounter, the training needs to spend a disproportionate amount of time looking at bets that never happen in practice. Bets of 2x pot definitely happen, so if I didn��t try to learn bets between pot and all in, the model might make some very funny predictions.
The thing about my model is that it learns to predict the best strategy �� or rather tries to predict the CFR strategy �� directly from the cards and bets made so far this hand. Nothing more.
In order to help it understand what the heck is going on in a specific hand situation, where changing a single card changes everything, I also asked the model to output guesses for several side tasks. The simple one was asking it to predict its own hand��s odds of making each of 11 poker hand categories: royal flush, straight flush, quads, full house, flush, straight, trips, two pair, big pair (jacks or better), small pair, or no pair. (An astute reader might pick up on the fact that I first started building this network to see how well it could learn to play Jacks-or-Better video poker!)
The more interesting bit happens when I ask the network also to predict its opponent��s hand. I��m not asking it to predict its opponent's cards exactly �� although it would not be terribly difficult to hack that �� but rather, to determine (say) an opponent��s odds of making a flush, on the given board, with the given bets made so far. And to determine an opponent��s odds of beating us if we were all in right now, based on the cards that the opponent is likely to hold currently. Actually, I ask the network to map the distribution of all-in odds against the opponent, so that it learns to look for merged and polarized ranges.
Asking the neural network to give details on what its hand is, and how it compares to what the opponent might have, not only makes the program's output a bit easier to understand, it also forces the network to learn which poker situations are similar to others that it has seen before in its training.
The thinking isn��t perfect, but I was pleasantly surprised by the ability of ��Poker-CNN�� to decipher some rare and tricky situations. For example here��s a hand in which Player2 holds 6?6? and turns bottom set. After a preflop raise and three-bet, it went check-check on the flop and then gets checked to him on the turn. He bets 80% of the pot, then gets raised all in:
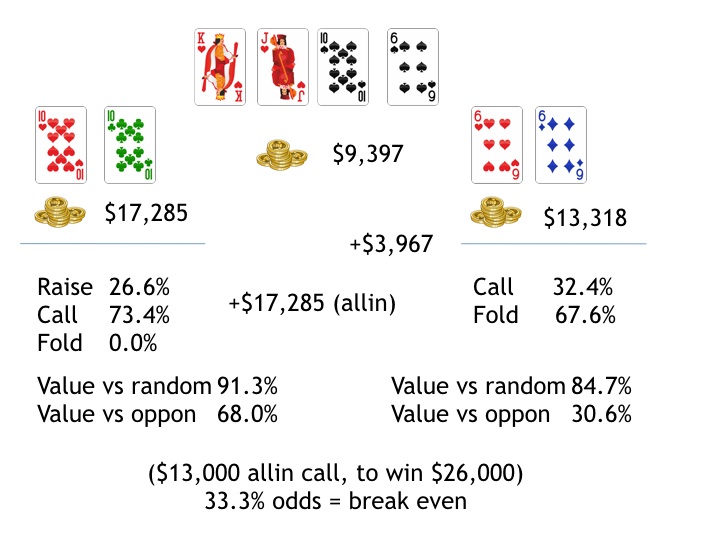
The neural network player��s thinking shows that he thinks he��s 84.7% against a random opponent, but only 30.6% against Player1, given the action during the hand. Too often, he��s far behind, given the preflop three-bet, the flop check, and the check-raise all in on the turn. (That��s a pretty strong line.)
Player2 folds, which makes sense given that he��s getting a bit less than 2-to-1 from the pot to call the all-in raise and he thinks he��s only 30% to win this in an all-in situation. But actually the neural network strategy calls for folding only 67.6% of the time. Which makes sense, too, in a way. If you folded every time that the odds aren��t with you, a good player could push you around by making bets that are just a little bit out of your calling range. That��s the challenge of building an unexplainable Nash-equilibrium finding player, and the difficulty of building a robust an AI that doesn��t yet have the ability to pick up on opponents' tendencies.
Learning More About Deep Neural Networks
My talk was well received. (You can see the full version of my AAAI presentation here.) A few students asked afterwards if they can try to build a poker AI based on deep neural networks themselves. The answer is yes �� in fact, I��ve published the Poker-CNN bot code as open source, although admittedly I need to clean the code up a little bit, to make it easier for others to use. I��ll also add an option for the bot to train for heads-up PLO, although I don��t have good hands for that game. Already, you can download the code, install the dependencies, and the code includes a pre-trained model that will tie for sixth at the ACPC.
What��s interesting about the deep neural network approach is that my system tries to learn poker as a person might. Last year ��Claudico�� competed against Doug Polk, Bjorn Li, Dong Kim, and Jason Les by crunching numbers for six months, then saving the resulting strategy into something like 3 TB (terabytes) of data. The 2016 ACPC winner learned 10^12 poker states (that��s one thousand billion situations), and saved space by representing each state efficiently in a single byte.
These approaches work, and by looking at a large and growing number of states, CFR is indeed inching closer toward an unbeatable heads-up no-limit hold��em strategy. However, it is still equaled in strength by human players, who obviously don��t have a trillion situations in mind. Somewhat reminiscent of a human brain, my network looks for patterns in hands and bets, and stores the result in just 1 MB of parameters. That��s about the size of an MP3 music file (and a short song, at that).
While the network isn��t yet as good as the best of CFR, I wonder whether letting ��Poker-CNN�� play against the equilibrium balancing systems for a few weeks wouldn��t get it pretty close. One of the more significant results of the past year in deep learning was a system built by Google Research, which ��distilled�� a huge deep learning model into a smaller model of 1/1000 of the size �� with equal or better performance, and a much faster runtime.
One of our most impressive abilities as humans, is learning from a few specific cases, generalizing that knowledge, and applying it to totally different examples of new information. We can see a person's face a single time, even in a photograph, and identify that person uniquely forever. Computers can��t do this quite yet. They usually need multiple positive examples, but with generalized image embeddings, they are getting closer. Studying artificial intelligence gives one a great appreciation for the intelligence of average humans.
Speaking of poker faces, I don��t think that it is an accident that four of this year��s top six ACPC AIs were developed in part by professional-level poker players:
- ��Slumbot�� was created by former Google engineer Eric Jackson, who cashed in last year��s WSOP Main Event (for a second time)
- ��Act1�� (which finished second in the Instant Runoff Competition) was created by a Carnegie Mellon Ph.D student who played winning online poker for year
- as mentioned, ��Hugh�� was developed by a mathematician with input from one of today��s well-known high-stakes players
- and ��Poker-CNN��... well, I used to play poker good!
We��re not quite there with general intelligence. Strong AI systems tend to be rather specific, and highly customized for a narrow task. But we��re getting closer.
Looking Back, Looking Ahead
I did not expect to win the AI competition, and just finishing in the middle of the pack �� losing to the equilibrium-finding bots by 2/3 less than folding every hand �� was a bit of a thrill.
I remember first reading about University of Alberta��s Poker Research Group ten years ago, in between playing hands of $30/$60 LHE on PartyPoker at the Columbia University computer lab when I probably should have been studying. Green Day��s American Idiot was on blast in my headphones, drowning out the noise of my lab mates playing Halo, just to paint a full picture.
I thought then about building a hold��em AI, but never got around to it. It was too easy to win as a human back then, although nobody, including me, won nearly as much as he or she could have. Success breeds complacency. Thankfully I didn��t win nearly enough to consider playing full-time, so instead I interviewed with Google, got an offer, and that was that.
Meanwhile the Alberta poker group grew. In the summer of 2007 they split a match against two poker pros in a four-session match of limit hold��em, and soon they moved into equilibrium-balancing methods to try to ��solve�� the heads-up game.

Like many important ideas, it all seems obvious in retrospect. It turned out that yes, limit hold��em is a small enough game to be able to find an unbeatable strategy, over all possible opponent responses. The Alberta research group, led by Professor Michael Bowling, did not limit themselves to poker, building tools for computers to master other computer games. These included building the Arcade Learning Environment (ALE) made famous by DeepMind (a division of Google) demonstrating that a single neural network could learn to play 50 different Atari games, many of them much better than a human.
The poker AI work, however, is Alberta��s bread and butter. While at the AAAI conference it was thrilling for me to lunch and grab beers with the authors of the poker AIs whom I��ve long admired.
Besides solving for an perfect equilibrium, soon to be graduating PhD students Michael Johanson and Nolan Bard have been working on versions of CFR that adjust to opponents, be those computer or human. It��s tough to get a human to play even a ��small sample�� of 10,000 heads up NLHE, so some of this work depends on fuzzy-worded player feedback.
It turns out that in LHE, humans do worst against an AI that is trained to treat pots that it wins as worth 107% of the actual pot size. This is not enough of an internal bonus to make it play too spewy, but it encourages more frequent aggressive actions, which are harder for a human to handle.
Meanwhile for NLHE, a simple fixed-size bonus any time that the computer bets instead of checking was viewed by humans as hardest to compete against, and also the most human, according to Johanson. Viliam Lisy (a post-doc, also at Alberta) chimed in that humans hate being forced to make extra decisions. Although to that I��d add �� as brilliantly explained by Andrew Brokos on a recent Thinking Poker podcast �� sometimes checking and making your opponent think about bluffing or giving up is the hardest decision that you can give him. (Boy, I��ve gotten that one wrong a few times!)
Universally, strong players think that CFR is too passive, even as they struggle to break even with the bots. Maybe poker really is just a nittier game than we want to admit. But for sure, these AIs are far from passing a poker ��Turing Test.�� (Maybe we should call it the ��Durrrr Test,�� not to be confused with another contest of a similar name.) Truth be told, it��s still not hard to tell after a few hands whether you��re playing a robot.
On the flip side, the poker AI veterans were happy to have me as new entry for their competition. It used to be hard and somewhat expensive to set up long matches against too many AIs. But with the continuing drop in prices for Amazon Web Services, any aspiring poker AI coders out there should know that they are welcome for next year��s contest. Start training your engines �� just remember that there��s a shot clock, so that we can get through 100,000+ hands for each player within a couple of weeks.
Under the surface of Alberta and CMU��s dominance is that a fourth equilibrium balancing system won the Uncapped Total Bankroll competition, ��Nyx TBR.�� I couldn��t quite understand what the authors of ��Nyx TBR�� did, even after two breakfasts with the author, Martin Schmid. From what he explained, they go out of their way to model occasional ��random moves�� by an opponent, and while their system seeks an overall equilibrium, it also tries to maximally exploit those ��out of sample�� situations. Thus although Nyx lost (by a small margin) to the top three finishers in the Competition Crosstable and Total Bankroll Competition, their system won maximally against non-CFR players, including my ��Poker-CNN.��
Meanwhile, the CMU team behind ��Claudico�� is leveraging the poker proof of concept to look for new applications of game theory. Walking back to the hotel after dinner, Professor Tuomas Sandholm told me how nice it is that nowadays everyone at these AI conferences knows about the Nash equilibrium. It saves him a lot of time in pitching his lab��s new ideas. These ideas include using game theory to model networks for organ donations, an important topic for which his colleagues recently won the Economics Nobel Prize. This isn��t to say that kidney donation is a game, but rather that modeling the reciprocal donations as a game with an objective that may be several moves away can be an effective tool for looking at a complex system of individual relationships.
Another area that Prof. Sandholm was super excited about was using equilibrium-finding methods to recommend treatments for serious diseases. Their idea is to treat the virus, or the cancer, as a villain in something like a heads-up poker game. (There��s a ��high stakes�� quip here that I perhaps should not make.) Maybe the better analogy is a dynamic version of Battleship, but what do I know? It would be great to hear that in a few years, some of these ideas might be working.
Tackling the Game of Go, and the Future of Poker AIs
The unequivocal star of the conference was rather closely related to poker. Following up on a big announcement last month, DeepMind��s Demis Hassabis used a keynote address to talk about AlphaGo, his team��s breakthrough AI for the Chinese board game Go, long thought to be very difficult for computers to play at a top human level.

Using a network similar to the one that I used for ��Poker-CNN�� (I based my poker system on DeepMind��s network design for Go, using early results in 2014), the researchers build a bot that defeated the European Go champion Fan Hui, five games out of five. They��ll be taking on the (human) world champion next.
The scientists started by looking at each grandmaster game of Go ever recorded, and asking their deep neural network to predict the next move that a strong player would make. Often, many moves are of similar long term value, so the network computes a probability over every stone that could be placed next on the board.
Once they had created a strong go AI player by predicting human experts�� moves, the scientists could generate more high-quality game data by having the network play itself millions of times. Even though go does not start with a random shuffle, by asking the computer players to vary their choices with an occasional semi-random move, they were able to explore a wide variety of positions, over many more games than any human player had ever seen.
As a final component, since AlphaGo predicts the likely next move(s), it can also ��look ahead�� to where the game might be going, and to evaluate those future positions as well, simulating strong play for both sides.
During his lecture, Dr. Hassabis explained that the final choices made against the human champion were based 50% on each board��s value as predicted by the neural network, and 50% on simulating several moves ahead with a ��Monte Carlo�� randomized look-ahead. Even without the rollouts simulation, AlphaGo can beat most strong Go players easily, which is a testament to the power of its positional understanding. (In a late development, just last night AlphaGo defeated Go champion Lee Se-dol in a much-publicized match in Seoul, South Korea �� read all about it in over at The Verge.)

It should be noted that Dr. Hassabis is himself a strong poker player. In fact he narrowly missed out on a WSOP final table �� in a $10,000 6-max. event, no less �� the last time he took a break from his executive duties to come to Las Vegas. He is also a strong Go player, but at this point his play is much, much weaker than the AlphaGo program that his team has built, as is everyone else on the project.
It isn��t much of a stretch, then, to say that poker-style thinking is prevalent at the highest levels of the artificial intelligence community. It was rumored around the conference that DeepMind might turn its focus next to a super-strong NLHE agent, beyond CFR, and possibly even one that adjusts to stack sizes and player tendencies so that it could play strong tournament poker under realistic conditions. Perhaps they��ve already built such a prototype, and are testing it against professional players in a bunker, subject to non-disclosure agreements.
My hope for the 2017 AAAI Conference is that I will no longer be able to beat my ��Poker-CNN�� in heads-up no-limit hold��em. By then it will be adjusting dynamically, and punishing me for the obvious leaks in my undisciplined game. I hope that it won��t even be close!
Nikolai Yakovenko is a professional poker player and software developer residing in Brooklyn, New York who helped create the ABC Open-Face Chinese Poker iPhone App.
Want to stay atop all the latest in the poker world? If so, make sure to get PokerNews updates on your social media outlets. Follow us on Twitter and find us on both Facebook and Google+!









